


More prompts, fewer codes, and we built this smart Telegram bookmark bot in 3 weeks
Not that we're on a budget. We just did it the more efficient way

👋 Hey, Mayvees here! Welcome to my hub. Each week I humbly tackle different concerns about anything related to building products, based on my humble experience. To support me on this journey, please subscribe to my Substack!
It’s SaveDay here, and we’re in the progress of building a Telegram bot for quick capturing any information, and retrieve them better. In case you want to try us out first, https://save.day/ is where you should visit for more 🙋♀️
So where did we start?
We started with our own pain points

To set the context:
We’re a team of avid learners. We even have a Slack channel to share knowledge and it’s the most active one
We were working on something different before, and it did not turn out quite well
When we decided to turn to something else, our boss stood up in front of us and said: “Why don’t we solve our own problems with managing our consumed information & knowledge?”
Fyi, his online nickname is @bookmark
Bookmarking is old school. Make it “everything-marking”
Bookmarking comes from the concept of marking a page in the book one’s currently reading, making it easier for them to access later
Books appeared from the ancient times, then the digital age of the 20th century brought every word to the Internet. Today we do not only consume words by reading. Youtube, TikTok, … have made videos a common source of information. Spotify, Apple, Google podcasts have found a need in consuming voice-only information while users can focus on doing something else,… Pinterest has persuaded that images are also what people seek for information. Social networks like Twitter or Facebook have cut the length of content usually seen with books, articles to valuable short posts
But bookmarking tools still remain the same as it was for books or the early phase of the Internet. Pocket, Raindrop, browser bookmarks still do what’s been done for over a decade:
They work for text-based links with a simple click just to save. For images, audio, videos,… if they do not come from a link, there’s no way to bookmark
They do not support searching for anything rather than text. But what’s the meaning of bookmarking if it does not help you access saved things easier?

Then off to potential users’ problems
Time was not much for hardly anything, so I planned out a quick research and asked the team to involve their own experience as well. The research aimed to understand the knowledge capturing journey of people with different needs

Some pain points are listed as below:
Consume a lot and in different forms, but cannot remember everything
Save content in different sources, and cannot remember where to find it
Bookmark/information storage now still requires keywords to search, which are hard to pull out
No way to search for information form rather than text (images/podcasts/videos/...)
Each person may remember a piece of information in different ways (some remember the color, some keywords, some main points,…). When conducting a research about how users remember the pieces of information they want to access again, some may pull out “an article about data with a green gecko”, “an image of 2 shiba dogs with Japanese style”, “a video interviewing Airbnb founder on travel”,….
Retrieval requires context. Everytime they seek for a piece of information they have to go through the original content to find it


Key points about their behaviors:
Some are super proactive when it comes to consuming information. They take time reading/listening,… and take notes, document them well (especially context) in their own PKMS (personal knowledge management system). They even link knowledge using Obsidian to access them easier later
Some love information but they do not have time or do not believe they need to build a PKMS for themselves. They just simply dump the information in messaging apps or notes or sometimes browser bookmarks to save them. And it turns out to be pretty bad for searching
Some consume information because it’s required, and outside that context they do not think this should be saved to access later
And we decided the Knowledge Sloth might be who we’re designing this for
Hook product = Telegram bot
Looking back at users’ journey, we saw an opportunity in messaging apps as a quick product to test the demand as users have the behavior of dumping links and files to messaging apps to save
What if they still dump it in a chat window but it can save the information and help them retrieve better than now?
And Telegram is a good start as:
Users do use it:
Telegram is one of the messaging apps that they send information to save
It’s a top messaging app. No one wants to build products on a dead platform
It’s an easy entry for us technically:
It’s super open so it’s easy for us to configure
Its bot features are well-supported for commands and flow operation
What this Telegram bot does is explained in the value proposition below

This bot covers 3 main feature sets:
Bookmarking:
Support various formats (links, images, audio, videos, files,…)
Searching:
Search for any format
Supports both lexical and semantic search for our memory-friendly search
After researching on how people remember their saved content, we pulled out attributes about the content, made sure each attribute is generated when bookmarking the information and searchable
Generated content:
Key points (written in Zettelkasten method) to quickly retrieve important points of the information
Mindmap (with the same purpose as key points, but to fit in with other people’s retrieval methods)
Images generated from key points for easier social sharing. This is built for people who share knowledge a lot with their teams, friends or on social media platforms as part of their jobs
For technical decisions:
Bot-User flow is configured in n8n - a no-code tool so that our operator can do it without a developer’s help
Generative content is powered by OpenAI API, but surely through a rigorous prompting phase by our prompt engineer (AKA our boss)
Hybrid search between lexical (Algolia) and semantic search. Embedding model for semantic search also comes from OpenAI
Database: Postgres, Pinecone (vector database), Neo4j (graph database)
And it’s finally somewhere in our journey

We have not launched yet, as mindmap is still on its way. But today we’re open on Telegram to try out for bookmarking, searching and generating key notes
Below is a brief demo of our features
Bookmark
Search
Get key points
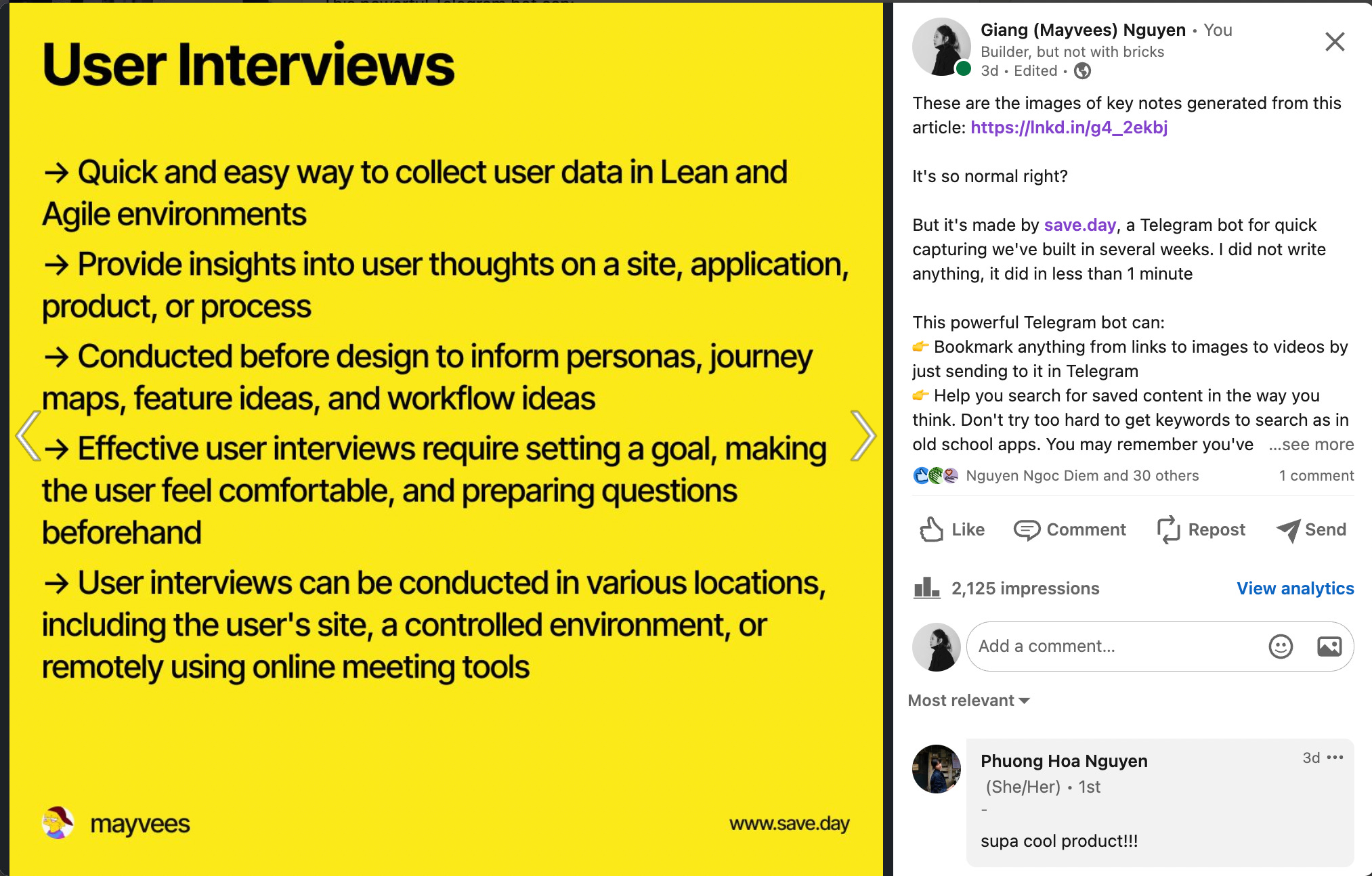
These are the images generated from key points of the article about UX that I have used to share on LinkedIn, super convenient
The hard things about hard things
Throughout our journey, we have been stuck at many points:
Building a message-based product is nothing near a usual app interface - which we have been so familiar with. It requires different mindset on UX, and considering the limitations of the message platform
We cut off the amount of code needed and change to a no-code platform to less rely on developers. We chose n8n and it has limitations as well, some have to be traded off
This is the first time we’ve worked intensively with OpenAI, and prompts are not just prompts. They require a lot of techniques to make the output satisfactory. We have learnt lessons in breaking chunks, generating key points, limiting tokens, optimizing performance,…
And all of these are being documented to be brought up in our next articles. So stay tuned for detailed posts!
What’s next?
Mindmap is on its way
Official launch for our product. Hope to receive feedbacks and support from you guys 🙋♀️
Asking for quick answers from saved content is what we’re considering
We never aim to be the next Notion or Obsidian, so integrating well with these apps for you guys to import/export data is on the list
More bots on more messaging apps to cover the touch points
And more to consider, you guys can comment your opinions here 👌
Try it at https://www.save.day/. It’s free 😀
Credit to @huy, @phuong, @co, @longbb, @thinh, @bit, @anhpm, @tradao, @zoe for building this together